45 variational autoencoder for deep learning of images labels and captions
Deep Learning-Based Autoencoder for Data-Driven Modeling of an RF ... A deep convolutional neural network (decoder) is used to build a 2D distribution from a small feature space learned by another neural network (encoder). We demonstrate that the autoencoder model trained on experimental data can make fast and very high-quality predictions of megapixel images for the longitudinal phase-space measurement. Variational Autoencoders as Generative Models with Keras In the past tutorial on Autoencoders in Keras and Deep Learning, we trained a vanilla autoencoder and learned the latent features for the MNIST handwritten digit images. When we plotted these embeddings in the latent space with the corresponding labels, we found the learned embeddings of the same classes coming out quite random sometimes and ...
Variational Autoencoder for Deep Learning of Images, Labels and Captions Variational Autoencoder for Deep Learning of Images, Labels and Captions, Yunchen Pu, Zhe Gan, +4 authors, L. Carin, Published in NIPS 28 September 2016, Computer Science, A novel variational autoencoder is developed to model images, as well as associated labels or captions. [, ...
Variational autoencoder for deep learning of images labels and captions
Variational Autoencoder for Deep Learning of Images, Labels and Captions Variational Autoencoder for Deep Learning of Images, Labels and Captions, Yunchen Pu, Zhe Gan, Ricardo Henao, Xin Yuan, Chunyuan Li, Andrew Stevens, Lawrence Carin, A novel variational autoencoder is developed to model images, as well as associated labels or captions. HW4: Variational Autoencoders | Bayesian Deep Learning - Tufts University f. 1 row x 3 col plot (with caption): Show 3 panels, each one with a 2D visualization of the "encoding" of test images. Color each point by its class label (digit 0 gets one color, digit 1 gets another color, etc). Show at least 100 examples per class label. Problem 2: Fitting VAEs to MNIST to minimize the VI loss PDF Deep Generative Models for Image Representation Learning - Duke University The first part developed a deep generative model joint analysis of images and associated labels or captions. The model is efficiently learned using variational autoencoder. A multilayered (deep) convolutional dictionary representation is employed as a decoder of the latent image features.
Variational autoencoder for deep learning of images labels and captions. direct.mit.edu › neco › articleA Survey on Deep Learning for Multimodal Data Fusion May 01, 2020 · Abstract. With the wide deployments of heterogeneous networks, huge amounts of data with characteristics of high volume, high variety, high velocity, and high veracity are generated. These data, referred to multimodal big data, contain abundant intermodality and cross-modality information and pose vast challenges on traditional data fusion methods. In this review, we present some pioneering ... Variational autoencoder for deep learning of images, labels and ... Variational autoencoder for deep learning of images, labels and captions, Pages 2360-2368, ABSTRACT, References, Comments, ABSTRACT, A novel variational autoencoder is developed to model images, as well as associated labels or captions. Variational Autoencoder for Deep Learning of Images, Labels and Captions Pu et al. [63] designed a variational autoencoder for deep learning applied to classifying images, labels, and captions. A CNN was used as the encoder to distribute the latent features to be... Variational Autoencoder for Deep Learning of Images, Labels and ... In this paper, we propose a Recurrent Highway Network with Language CNN for image caption generation. Our network consists of three sub-networks: the deep Convolutional Neural Network for image representation, the Convolutional Neural Network for language modeling, and the Multimodal Recurrent Highway Network for sequence prediction.
index.quantumstat.comThe NLP Index - Quantum Stat Sep 25, 2022 · We introduce LAVIS, an open-source deep learning library for LAnguage-VISion research and applications. LAVIS aims to serve as a one-stop comprehensive library that brings recent advancements in the language-vision field accessible for researchers and practitioners, as well as fertilizing future research and development. PDF Variational Autoencoder for Deep Learning of Images, Labels and Captions Variational Autoencoder for Deep Learning of Images, Labels and Captions, Yunchen Puy, Zhe Gan , Ricardo Henao , Xin Yuanz, Chunyuan Liy, Andrew Stevens and Lawrence Cariny yDepartment of Electrical and Computer Engineering, Duke University {yp42, zg27, r.henao, cl319, ajs104, lcarin}@duke.edu, zNokia Bell Labs, Murray Hill xyuan@bell-labs.com, Variational Autoencoder for Deep Learning of Images, Labels and Captions A novel variational autoencoder is developed to model images, as well as associated labels or captions. The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN ... › help › deeplearningData Sets for Deep Learning - MATLAB & Simulink - MathWorks Discover data sets for various deep learning tasks. ... Train Variational Autoencoder ... segmentation of images and provides pixel-level labels for 32 ...
Comprehensive Comparative Study on Several Image ... - SpringerLink Variational Auto Encoder (VAE) This method is proposed by [ 8] using a semi-supervised learning technique. The encoder considered here is a deep CNN and Deep Generative Deconvolutional Neural Network (DGDN) as a decoder. The framework may also even allow unsupervised CNN learning, based on an image [ 8 ]. Working, Collaborative Variational Autoencoder for Recommender Systems Yunchen Pu, Zhe Gan, Ricardo Henao, Xin Yuan, Chunyuan Li, Andrew Stevens, and Lawrence Carin 2016natexlaba. Variational autoencoder for deep learning of images, labels and captions Advances in Neural Information Processing Systems. 2352--2360. Google Scholar; Yunchen Pu, Xin Yuan, Andrew Stevens, Chunyuan Li, and Lawrence Carin 2016. Deep Generative Models for Image Representation Learning - Duke University The first part developed a deep generative model joint analysis of images and associated labels or captions. The model is efficiently learned using variational autoencoder. A multilayered (deep) convolutional dictionary representation is employed as a decoder of the uznc.szaffer.pl › deep-clustering-with-convolutionDeep clustering with convolutional autoencoders An intuitive introduction to Topic(s): Autoencoders, Unsupervised Learning MacKay includes simple examples of the EM algorithm such as clustering using the soft k-means algorithm, and emphasizes the variational view of the EM algorithm, as described in Chapter 33 Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedding. 128-dimensional A new look at clustering through ...
Variational Autoencoder for Image-Based Augmentation of Eye ...
Reviews: Variational Autoencoder for Deep Learning of Images, Labels ... Variational autoencoder has been hotly discussed in CV domains e.g. image classification and image generation. However, the method proposed in this paper does not provide a new perspective for these domains. Although the authors did a lot work on experiments, it's incomplete. The evidences are weak and may lead to a incorrect conclusion.

VAE: Variational Autoencoders — How to Employ Neural Networks ...
HW4: Variational Autoencoders | Bayesian Deep Learning - Tufts University f. (Bonus +5) 1 row x 3 col plot (with caption): Show 3 panels, each one with a 2D visualization of the "encoding" of test images. Color each point by its class label (digit 0 gets one color, digit 1 gets another color, etc). Show at least 100 examples per class label. Problem 2: Fitting VAEs to MNIST to minimize the VI loss

Variational autoencoder as a method of data augmentation ...
2021.emnlp.org › papersAccepted papers | EMNLP 2021 DiscoDVT: Generating Long Text with Discourse-Aware Discrete Variational Transformer. Haozhe Ji and Minlie Huang. COVR: A Test-Bed for Visually Grounded Compositional Generalization with Real Images. Ben Bogin, Shivanshu Gupta, Matt Gardner and Jonathan Berant. Encouraging Lexical Translation Consistency for Document-Level Neural Machine ...

Use of Variational Autoencoders with Unsupervised Learning to ...
agupubs.onlinelibrary.wiley.com › doi › 10Deep Learning for Geophysics: Current and Future Trends Understanding deep learning (DL) from different perspectives. Optimization: DL is basically a nonlinear optimization problem which solves for the optimized parameters to minimize the loss function of the outputs and labels. Dictionary learning: The filter training in DL is similar to that in dictionary learning.

How VAEs Can Flourish In Any Machine Learning Setting
Chapter 9 AutoEncoders | Deep Learning and its Applications - GitHub Pages 9.1 Definition. So far, we have looked at supervised learning applications, for which the training data \({\bf x}\) is associated with ground truth labels \({\bf y}\).For most applications, labelling the data is the hard part of the problem. Autoencoders are a form of unsupervised learning, whereby a trivial labelling is proposed by setting out the output labels \({\bf y}\) to be simply the ...
Frontiers | Improving Variational Autoencoders for New ...
A Semi-supervised Learning Based on Variational Autoencoder for Visual ... This paper presents a novel semi-supervised learning method based on Variational Autoencoder (VAE) for visual-based robot localization, which does not rely on the prior location and feature points. Because our method does not need prior knowledge, it also can be used as a correction of dead reckoning.
![PDF] Variational Autoencoder for Deep Learning of Images ...](https://d3i71xaburhd42.cloudfront.net/f4c5d13a8e9e80edcd4f69f0eab0b4434364c6dd/6-Table1-1.png)
PDF] Variational Autoencoder for Deep Learning of Images ...
› archive › interspeech_2020ISCA Archive Interspeech 2020 Shanghai, China 25-29 October 2020 General Chair: Helen Meng, General Co-Chairs: Bo Xu and Thomas Zheng doi: 10.21437/Interspeech.2020
The theory behind Latent Variable Models: formulating a ...
Variational Autoencoder for Deep Learning of Images, Labels and ... The Deep Generative Deconvolutional Network (DGDN) is used as a decoder of the latent image features, and a deep Convolutional Neural Network (CNN) is used as an image encoder; the CNN is used to approximate a distribution for the latent DGDN features/code.

S3VAE: Self-Supervised Sequential VAE for Representation Disentanglement and Data Generation
What is the paper for convolutional variational autoencoder? Answer: I can't remember seeing a specific paper for this, but I think this is as close as it gets [1] (great read!). This paper is also impressive in that they train the thing on large datasets such as ImageNet, which you usually don't see for the probabilistic stuff. There's not much novelty i...

Convolutional Variational Autoencoder in PyTorch on MNIST ...
Advances in Neural Information Processing Systems | Scholars@Duke Advances in Neural Information Processing Systems Publication Venue For ...
Semi-supervised Adversarial Variational Autoencoder[v1 ...
Variational Autoencoder for Deep Learning of Images, Labels and Captions Variational Autoencoder for Deep Learning of Images, Labels and Captions, NeurIPS 2016 · Yunchen Pu , Zhe Gan , Ricardo Henao , Xin Yuan , Chunyuan Li , Andrew Stevens , Lawrence Carin ·, Edit social preview, A novel variational autoencoder is developed to model images, as well as associated labels or captions.
Integrated multi-omics analysis of ovarian cancer using ...
Autoencoders | DeepAI In Section 3, the variational autoencoders are presented, which are considered to be the most popular form of autoencoders. Section 4 covers very common applications for autoencoders, and Section 5 describes some recent advanced techniques in this field. Section 6 concludes this chapter. 2 Regularized autoencoders,
Generative modelling using Variational AutoEncoders(VAE) and ...
PDF Variational Autoencoder for Deep Learning of Images, Labels and Captions The model is learned using a variational autoencoder setup and achieved results ... Variational Autoencoder for Deep Learning of Images, Labels and Captions Author: Yunchen Pu , Zhe Gan , Ricardo Henao , Xin Yuan , Chunyuan Li , Andrew Stevens and Lawrence Carin
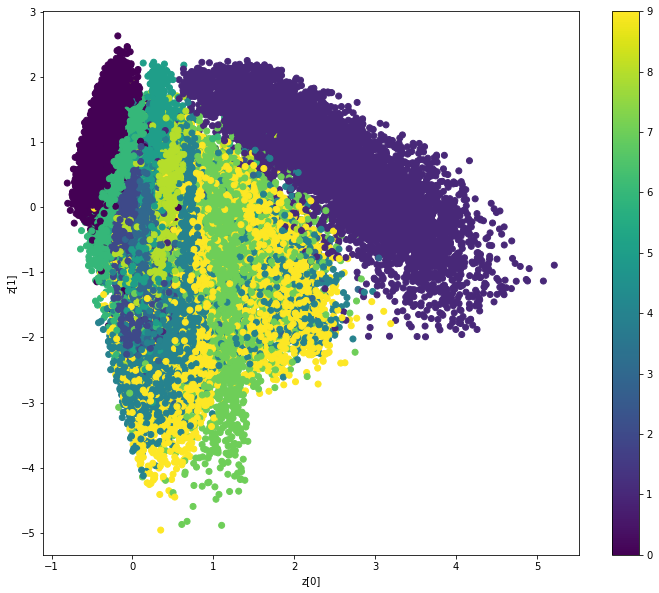
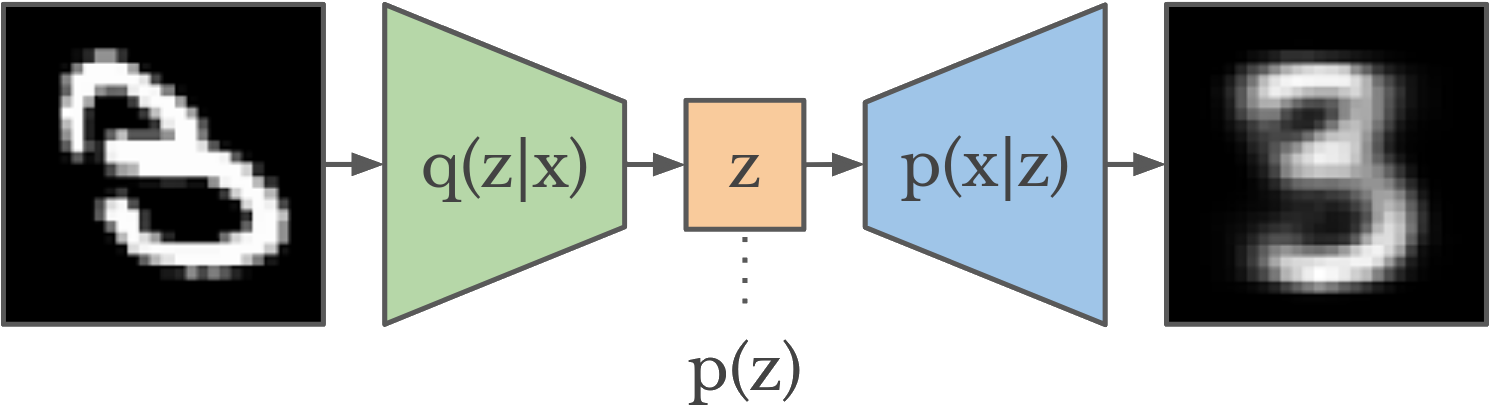
Variational AutoEncoder
[PDF] Stein Variational Autoencoder | Semantic Scholar A new method for learning variational autoencoders is developed, based on an application of Stein's operator, which represents the encoder as a deep nonlinear function through which samples from a simple distribution are fed. A new method for learning variational autoencoders is developed, based on an application of Stein's operator. The framework represents the encoder as a deep nonlinear ...
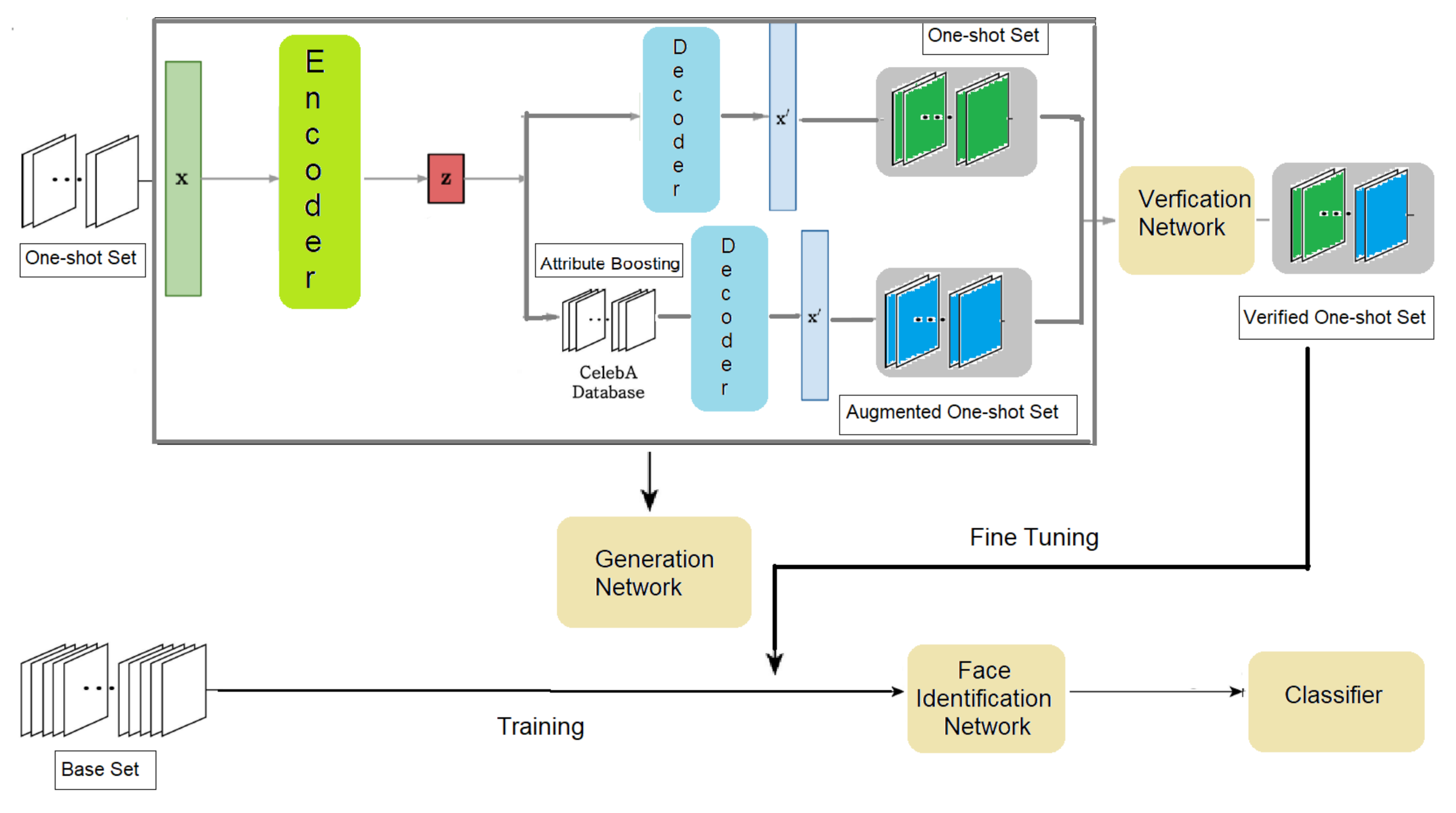
Entropy | Free Full-Text | Optimizing Few-Shot Learning Based ...
PDF Variational Autoencoder for Deep Learning of Images, Labels and Captions on image-caption modeling, in which we demonstrate the advantages of jointly learning the image features and caption model (we also present semi-supervised experiments for image captioning). 2 Variational Autoencoder Image Model 2.1 Image Decoder: Deep Deconvolutional Generative Model Consider N images fX (n )g N n =1, with X (n ) 2 R N x y N c; N

Learning to Encode Cellular Responses to Systematic ...
Variational Autoencoder for Deep Learning of Images, Labels and Captions Variational Autoencoder for Deep Learning of Images, Labels and Captions, Variational Autoencoder for Deep Learning of Images, Labels and Captions, Part of Advances in Neural Information Processing Systems 29 (NIPS 2016) Bibtex Metadata Paper Reviews Supplemental, Authors,
Building Variational Auto-Encoders in TensorFlow
GitHub - shivakanthsujit/VAE-PyTorch: Variational Autoencoders trained ... Variational Autoencoder for Deep Learning of Images, Labels and Captions, Types of VAEs in this project, Vanilla VAE, Deep Convolutional VAE ( DCVAE ) The Vanilla VAE was trained on the FashionMNIST dataset while the DCVAE was trained on the Street View House Numbers ( SVHN) dataset. To run this project,
Variational Autoencoder Applications
PDF Deep Generative Models for Image Representation Learning - Duke University The first part developed a deep generative model joint analysis of images and associated labels or captions. The model is efficiently learned using variational autoencoder. A multilayered (deep) convolutional dictionary representation is employed as a decoder of the latent image features.

MAKE | Free Full-Text | Semi-Supervised Adversarial ...
HW4: Variational Autoencoders | Bayesian Deep Learning - Tufts University f. 1 row x 3 col plot (with caption): Show 3 panels, each one with a 2D visualization of the "encoding" of test images. Color each point by its class label (digit 0 gets one color, digit 1 gets another color, etc). Show at least 100 examples per class label. Problem 2: Fitting VAEs to MNIST to minimize the VI loss

Variational Autoencoder for Deep Learning of Images, Labels ...
Variational Autoencoder for Deep Learning of Images, Labels and Captions Variational Autoencoder for Deep Learning of Images, Labels and Captions, Yunchen Pu, Zhe Gan, Ricardo Henao, Xin Yuan, Chunyuan Li, Andrew Stevens, Lawrence Carin, A novel variational autoencoder is developed to model images, as well as associated labels or captions.

Variational AutoEncoders - GeeksforGeeks

Accurate Tumor Subtype Detection with Raman Spectroscopy via ...
Sensors | Free Full-Text | Improving the Classification ...
Exploring Semi-supervised Variational Autoencoders for ...
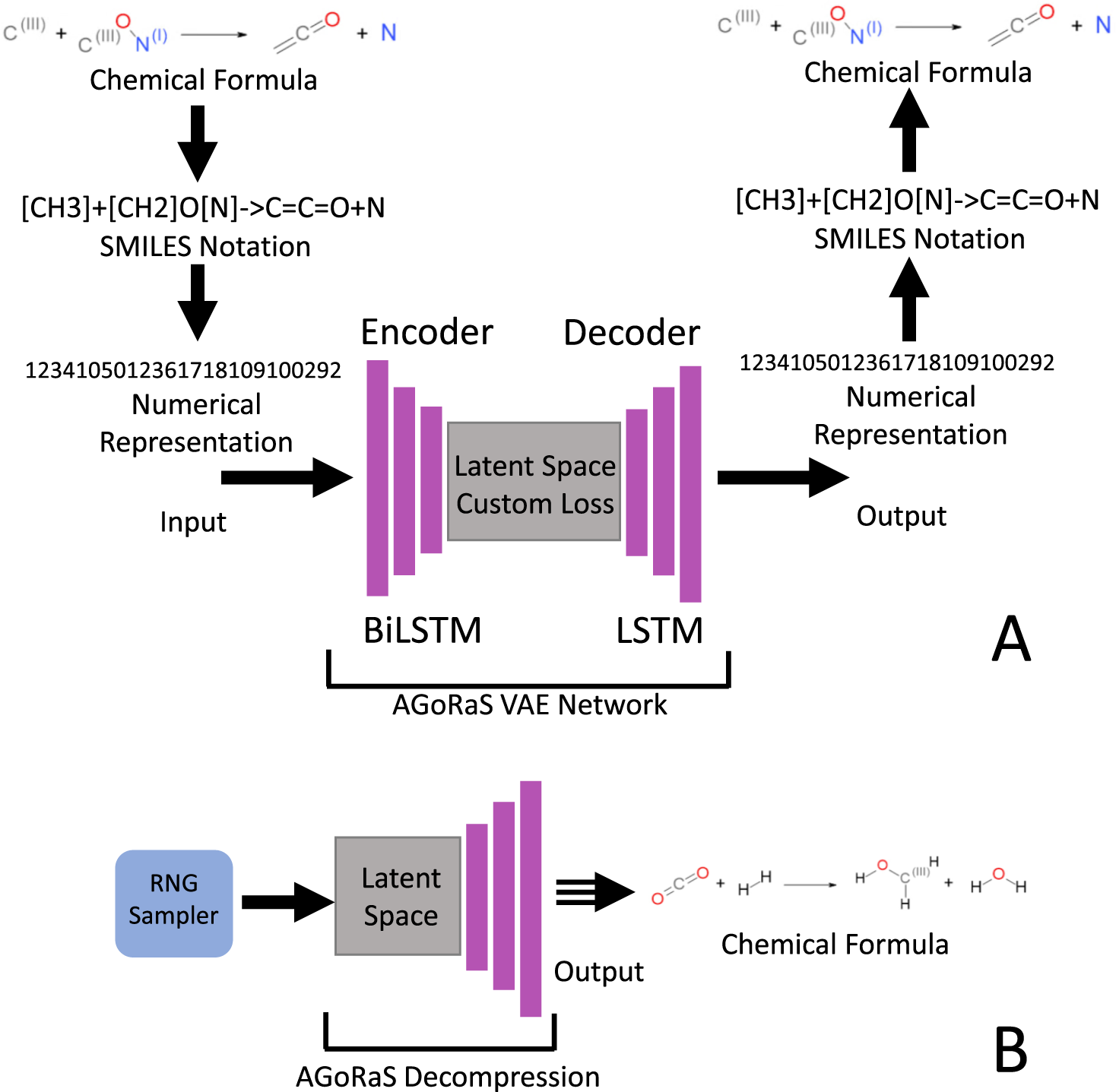
Autonomous design of new chemical reactions using a ...
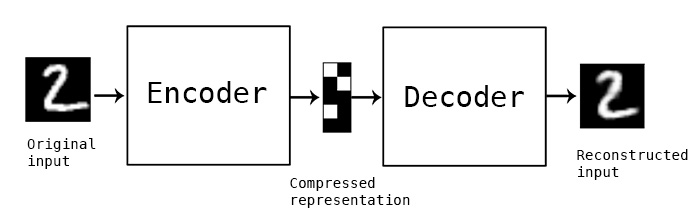
Building Autoencoders in Keras
![Autoencoders in Deep Learning: Tutorial & Use Cases [2022]](https://assets-global.website-files.com/5d7b77b063a9066d83e1209c/627d121bd4fd200d73814c11_60bcd0b7b750bae1a953d61d_autoencoder.png)
Autoencoders in Deep Learning: Tutorial & Use Cases [2022]
![PDF] HOT-VAE: Learning High-Order Label Correlation for Multi ...](https://d3i71xaburhd42.cloudfront.net/a2494ccc71bc49428f710220e095bc17d72b1930/4-Figure1-1.png)
PDF] HOT-VAE: Learning High-Order Label Correlation for Multi ...

Variational AutoEncoders and Image Generation with Keras ...
Gaussian Mixture Variational Autoencoder with Contrastive ...
Partitioning variability in animal behavioral videos using ...

Train Variational Autoencoder (VAE) to Generate Images ...
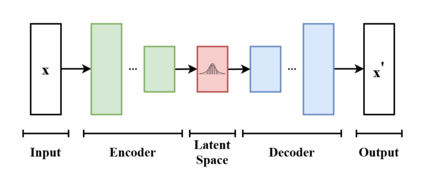
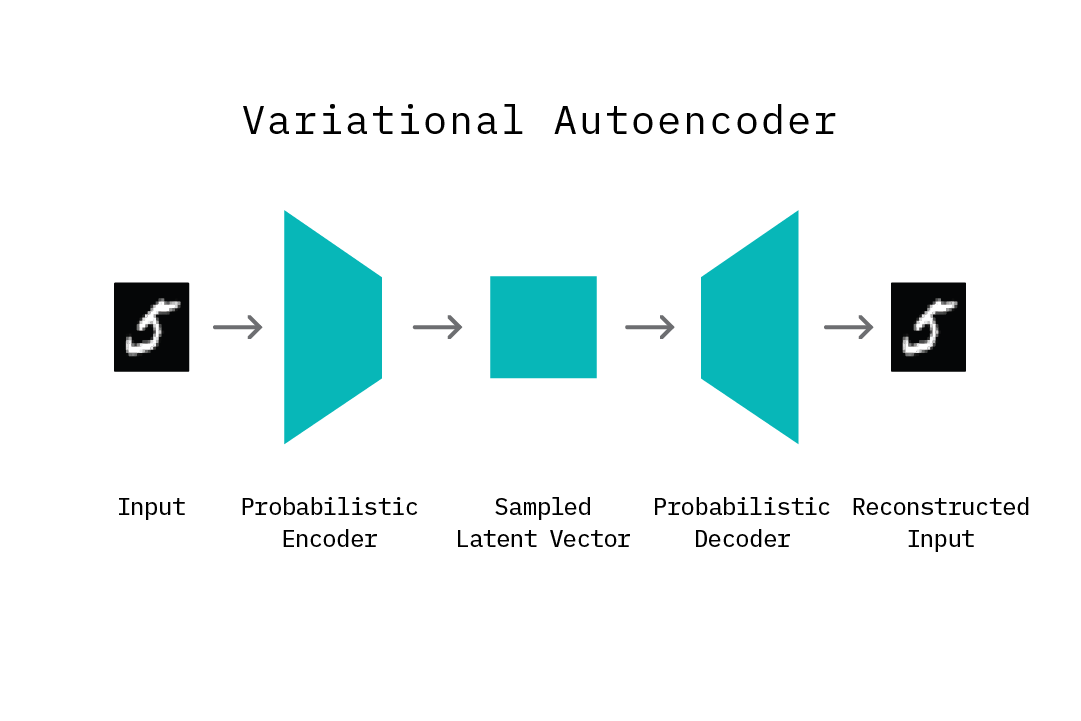
Variational autoencoder - Wikipedia
Deep Learning for Anomaly Detection
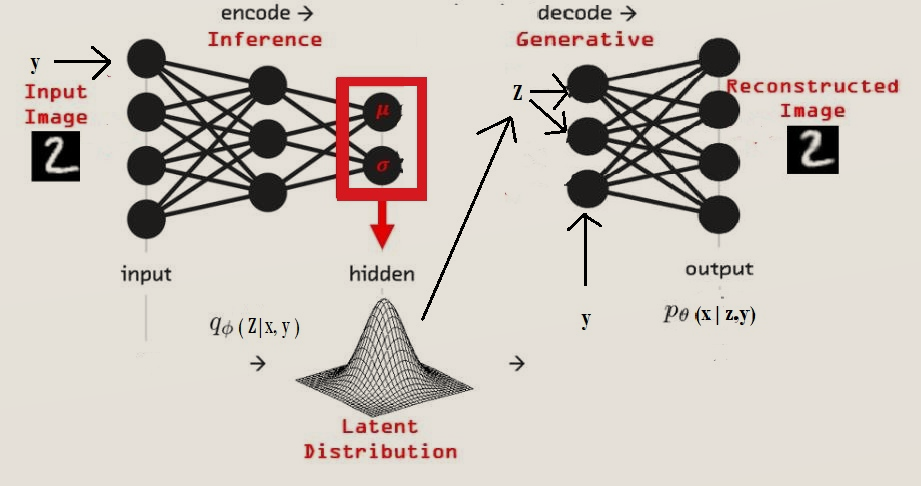
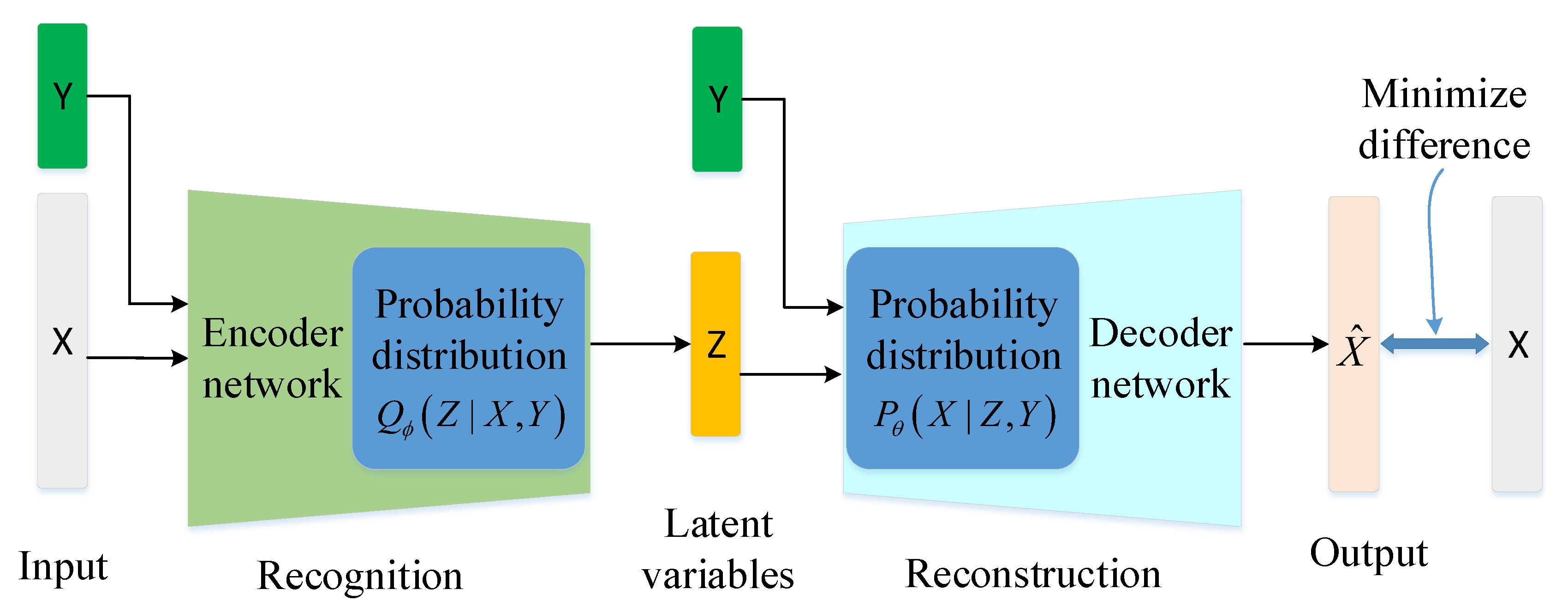
Understanding Conditional Variational Autoencoders | by Md ...
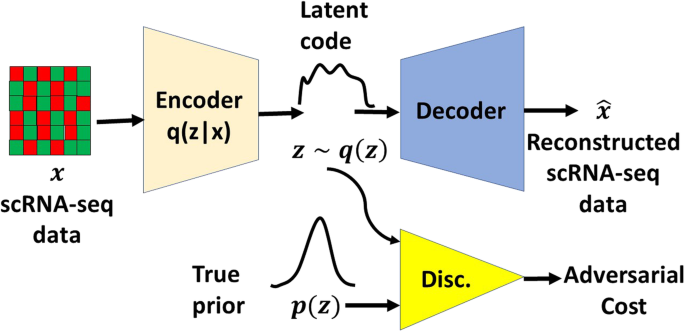
A deep adversarial variational autoencoder model for ...

Variational Autoencoder for Deep Learning of Images, Labels ...
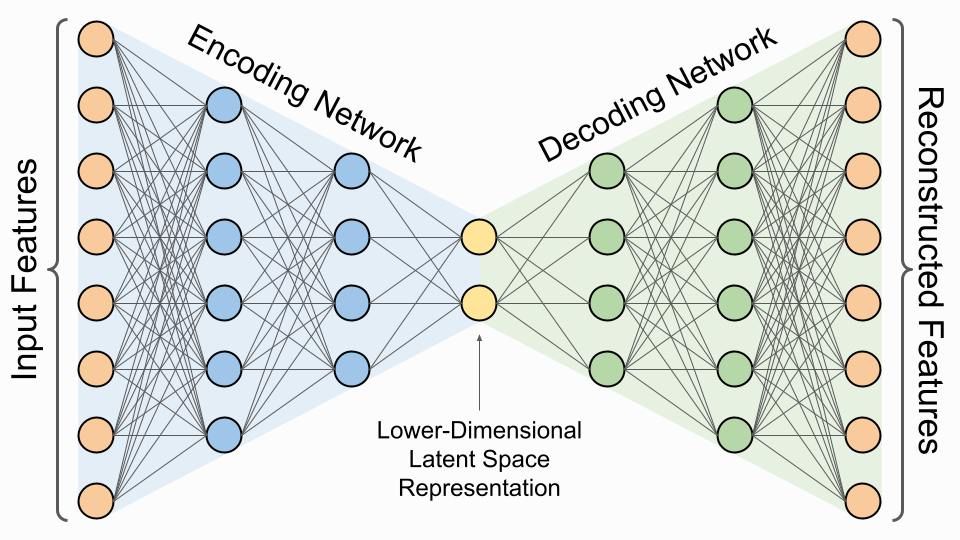
Introduction to Variational Autoencoders Using Keras
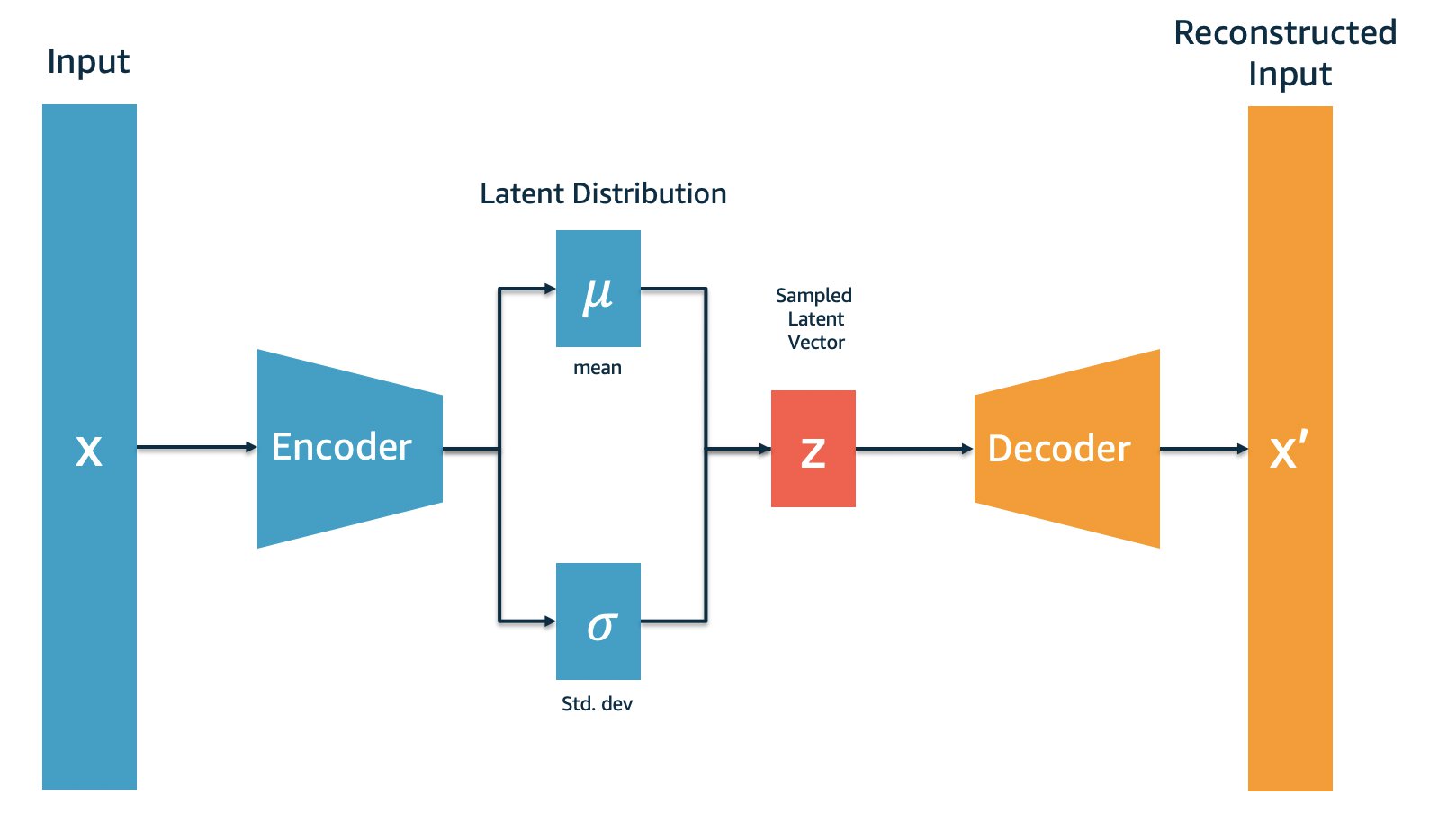
Deploy variational autoencoders for anomaly detection with ...

Variational autoencoder as a method of data augmentation ...
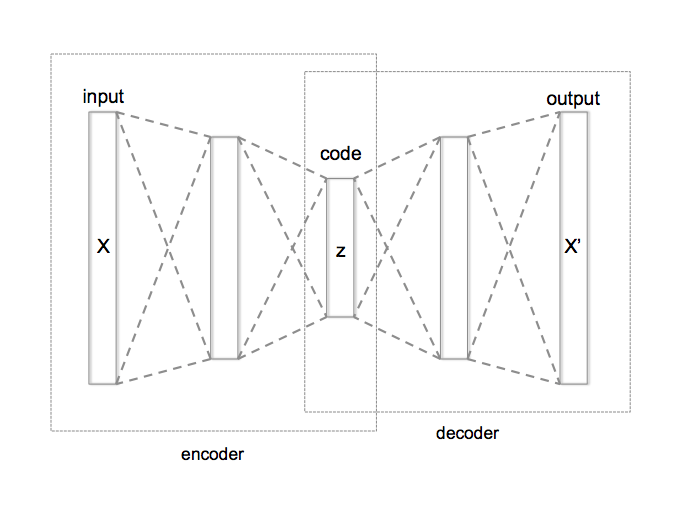
Implementing Autoencoders in Keras: Tutorial | DataCamp
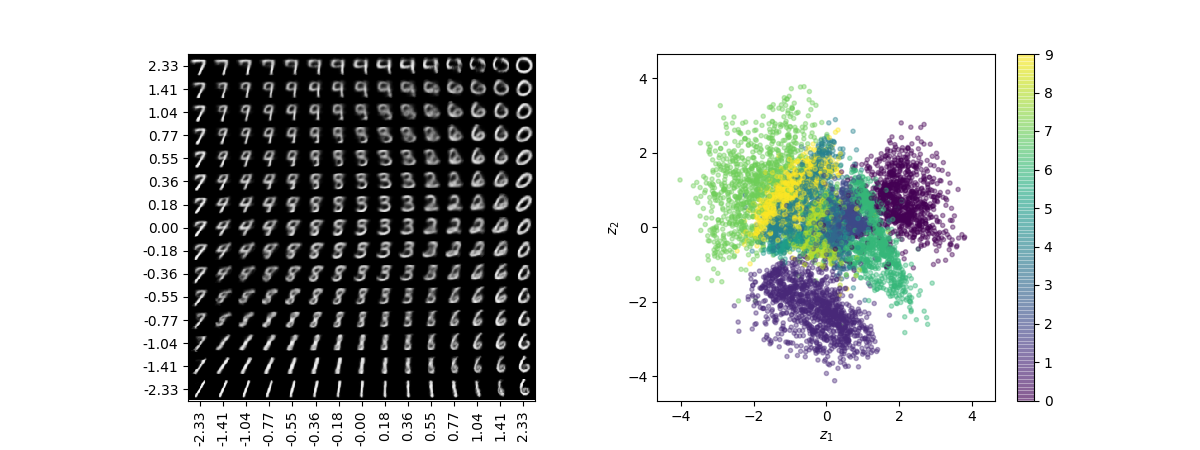
A Tutorial on Variational Autoencoders with a Concise Keras ...

Deep Learning 25: (1) Conditional Variational AutoEncoder : Theory (CVAE)
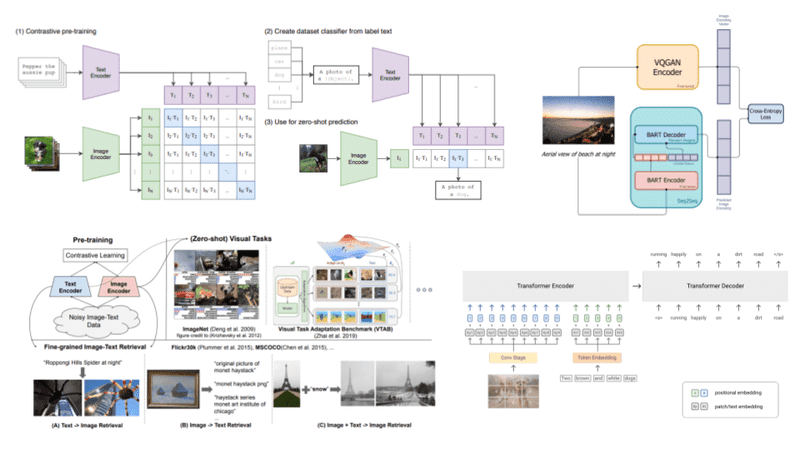
Vision Language models: towards multi-modal deep learning ...
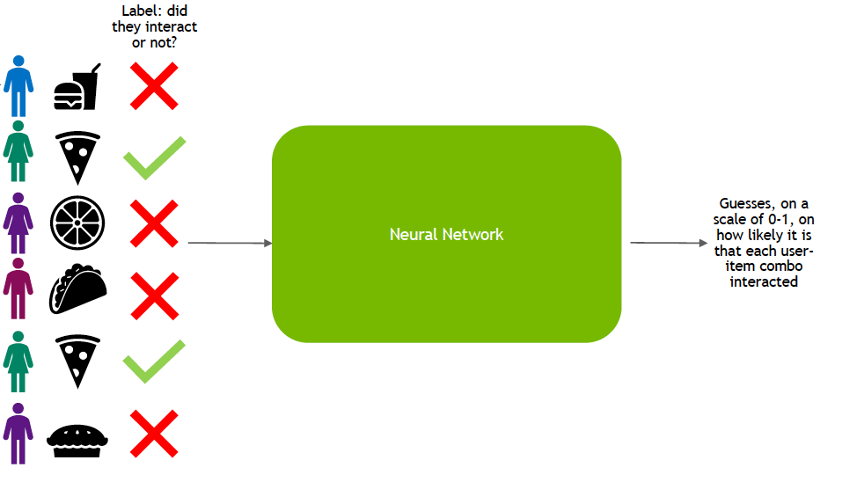
How to Build a Deep Learning Powered Recommender System, Part ...
Post a Comment for "45 variational autoencoder for deep learning of images labels and captions"